
What is a crawler?
A crawler (also called a spider, web crawler, or bot) is an automated program used by search engines such as Google and Microsoft’s Bing to discover and analyze content across the internet. Its primary job is to visit websites, read their content, follow links to other pages, and send that information back to the search engine’s database so it can be organized and made searchable.
Think of a search engine bot as a digital librarian. Imagine a librarian who travels to every bookstore and library in the world, reads every book, takes notes about what each book contains, and then organizes everything into a giant catalog. When someone searches for a topic, the librarian already knows which books are most relevant. Search engine crawlers perform a similar task for websites and web pages.
Every day, search engine bots scan billions of pages across the web. They read text, headings, images, metadata, internal links, and other important elements to understand what each page is about. They also discover new content by following links from one page to another, helping search engines stay updated as websites publish new pages or update existing ones.
Without crawlers, search engines would have no efficient way to find, understand, or organize the vast amount of information available online. They are the first step in the process that allows websites to appear in search results, making them a critical part of how modern search engines work.
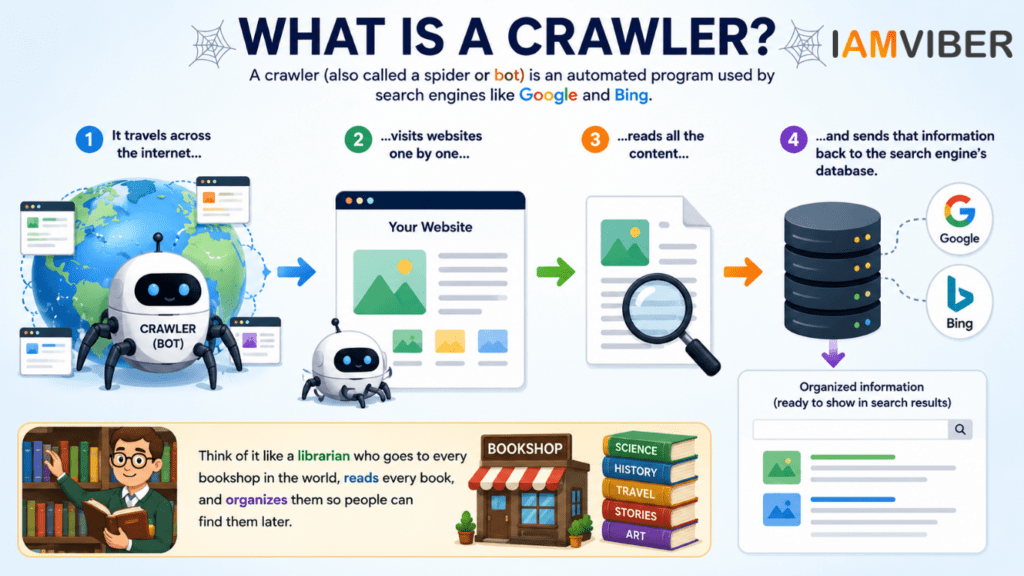
How does a crawler actually work?
Understanding how a search engine bot works can help you make smarter decisions about your website’s SEO and technical performance. Many website owners assume that search engines automatically understand everything on their site, but the reality is more structured. Crawlers follow a specific process every time they visit a website, gathering information and helping search engines determine what content should appear in search results.
The process is not random. Search engine bots systematically move across the web, discovering new pages, analyzing content, and updating their records whenever changes occur. Every page that appears in search results has usually gone through this crawling process first.
Here’s how the process works step by step:
It starts with a list of known URLs
Google’s crawler begins with a list of web addresses it already knows about. These could be sites it has visited before or new links shared by other websites.
It follows links from page to page
Just like how you click one article and find yourself reading another 20 minutes later, the crawler moves across the internet by following hyperlinks. Every link on your page is a potential path it will travel.
It reads your entire page
When the search engine bot lands on your page, it reads everything: your text, headings, image descriptions, internal links, and even the code that builds your page. Nothing is hidden from it.
It indexes the content
All of that information gets stored in Google’s index — a giant database containing information about billions of web pages. This step is called indexing, and it is what makes your page searchable.
It categorizes what your page is about
Based on the words, structure, and context of your content, the crawler helps Google understand your page’s topic, its relevance, and who should see it in search results.
It comes back regularly
Search engine bots do not visit just once. They return repeatedly to check for new content and updates.
It stores the data
Everything it finds gets saved in Google’s massive database. This is called “indexing.”
It understands your topic
Based on your keywords and content, it figures out what your page is about and who should see it.
It helps decide your rank
The data it collects feeds directly into Google’s ranking system, which decides where your page appears in search results.
Common search engine bot problems that hurt businesses
Most search engine bots issues are invisible to the naked eye — your website looks perfectly fine to a human visitor, but the crawler is silently struggling. Here are the most common problems and what they mean for your business:
Blocked pages in robots.txt — This is a small file on your website that tells crawlers which pages to visit and which to avoid. A single wrong setting can accidentally block your entire site from being crawled.
Broken links — When a crawler follows a link and lands on a page that no longer exists, it hits a dead end. Too many broken links slow down crawling and signal poor site quality to Google.
Slow page speed — Google gives each website a limited crawl budget — the number of pages it will crawl in one visit. If your site loads slowly, crawlers waste their budget waiting and leave before seeing all your pages.
Poor mobile experience — Google now primarily uses its mobile crawler. If your site is not optimized for phones, it gets crawled less effectively — directly hurting your rankings.
Duplicate content — If the same content appears on multiple pages of your site, crawlers get confused about which version to index. This can split your ranking potential and weaken your overall SEO.
Conclusion
Search engine bots are the foundation of how websites get discovered online. Before your content can rank, generate traffic, or attract customers, it must first be crawled and indexed by search engines. Understanding how crawlers work helps you identify technical issues that may be preventing your pages from appearing in search results.
By maintaining a search engine bot -friendly website, fixing broken links, improving page speed, optimizing for mobile devices, and avoiding duplicate content, you make it easier for search engines to understand and index your content. The easier your site is to crawl, the better your chances of achieving stronger visibility, higher rankings, and consistent organic traffic. In SEO, great content is important—but if search engine crawlers cannot properly access and understand your pages, even the best content may never reach its audience. That’s why crawlability should be a core part of every website’s SEO strategy.

